A Scenario to Ponder #8
This time its an interesting question. You will have to come up with a seemingly impossible query, which is pretty simple to implement in SQL Server 2005 :)
Lets say I have a table like this in a SQL Server 2000 box:
create table #answers (val1 char(1), val2 char(1))
And the following rows
insert into #answers values('X','A')
insert into #answers values('X','A')
insert into #answers values('X','A')
insert into #answers values('X','A')
insert into #answers values('X','A')
insert into #answers values('X','A')
insert into #answers values('X','A')
insert into #answers values('X','B')
insert into #answers values('X','B')
insert into #answers values('X','B')
insert into #answers values('X','B')
insert into #answers values('Y','B')
insert into #answers values('Y','C')
insert into #answers values('Y','C')
insert into #answers values('Y','C')
insert into #answers values('Y','C')
insert into #answers values('Y','D')
Now I want to write a query to select the 2 columns including 2 more columns val1cnt and val2cnt. The output I am expecting is given below.
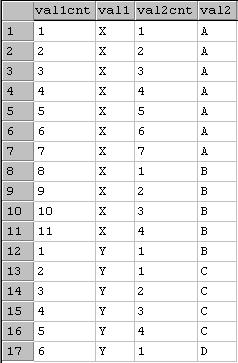 Points To Note:
Points To Note:
- val2cnt will be incremented by 1 for every repeating value of val2 and reseeded for every change in val2
- val1cnt will be incremented by 1 for every repeating value of val1 ordered by val2, val2cnt and will be reseeded for every change in val1
- val1 and val1cnt can uniquely identify a row in the output.


4 comments:
select row_number() Over(partition by Val1 order by Val1) as Val1Cnt,
Val1,
row_number() over (Partition by Val1,Val2 order by Val1,Val2) as Val2Cnt,
Val2
from #answers
Hi Bhushan,
Thanks for the answer. This solution will, indeed, work in SQL Server 2005. But, I am looking for an answer in SQL Server 2000, which, unfortunately, doesn't have the OLAP extension that you have used.
Here's an answer for you, but it does become quite inefficient quite quickly. If you have too many rows you need to apply this on, you'd want the temporary table.
It should be quite clear how this works...
select v.val1, v.val2, n.num as val1cnt, n.num + v.offset as val2cnt
from
(
select
d.val1,
d.val2,
count(*) as cnt,
(select count(*) from #answers d2 where d2.val1 = d.val1 and d2.val2 < d.val2) as offset
from #answers d
group by d.val1, d.val2
) v
join
dbo.nums n
on n.num <= v.cnt
order by v.val1, v.val2
Here is my solution.
select count(*) as val1cnt, x.val1,x.val2cnt,x.val2
from
(
select val1, number as val2cnt,val2 from
(
select val1,val2,count(*) as cnt from #answers
group by val1,val2
) a, numbers b where a.cnt >= number ) X,
(select val1, number as val2cnt,val2 from
(
select val1,val2,count(*) as cnt from #answers
group by val1,val2
) a, numbers b where a.cnt >= number) Y
where ((X.val2cnt >= y.val2cnt and x.val2 = y.val2)
or (X.val2 > y.val2))
and x.val1 = y.val1
group by x.val1,x.val2cnt,x.val2
order by x.val1,val1cnt,x.val2,x.val2cnt
Though, its similar in idea to Rob's solution, his implementation is much cleaner than mine. And using a temp table will definitely improve performance.
Way to go, Rob!
Post a Comment